(photo credit: David Marcu via unsplash)
(photo credit: David Marcu via unsplash)
There are plenty of reasons why one would want to find solitude in the wilderness, from the therapeutic effects of being immersed in nature, to not wanting to contribute to trail degradation and soil erosion on busier trails.
Now more than ever the reprieve of the outdoors is greatly needed. But in a post-COVID 19 world, where it can be practically impossible to maintain proper social distancing measures when passing hikers on a narrow trail, it is especially important to find less frequented trails to hike.
I set out on a mission to use data science and machine learning to find the best little-known trails in America.
The Approach
If you’re anything like me, before you go anywhere or buy anything, you’re going to read all the reviews.
When I first approached this project, I wanted to answer the question, “What makes a trail good?” That is, what combination of features and statistics about a trail would lead to it having a high overall rating?
What I pretty quickly found out though, is that across the 35,000 trails I scraped and analyzed, basically all of them were rated “pretty good” — that is, with an average user rating of 4.2 out of 5 stars and standard deviation of less than 0.6, it was really hard to distinguish which trails were excellent, and which were just okay, from their 5-star rating alone.

What there was huge variation in across all the trails though, was their popularity as represented by the total number of reviews each trail had. While the vast majority of trails had only 100 or so reviews, a select few had several thousand! What was making these trails so popular?

I thus pivoted to try to predict not the rating of a trail, but instead determine, via a data-driven model, the relationship between the various features of a given trail and its popularity. In finding commonalities, I could then apply that model to unpopular trails, to find which ones check all the same boxes and are likely to be great, even though they haven’t been discovered yet.
Methodology
) With Selenium and Beautiful Soup, use web scraping to obtain trail data about 35,000 trails in the United States. This included information about the length of the hike, its elevation gain, its location, and a list of all of the natural features (such as waterfall, wild flowers, paving) the trail had.
) Clean this data and create a Pandas DataFrame. This included one-hot encoding dummy variables for all of categorical feature columns.
) Utilize the VADER Sentiment Analysis module to analyze the text reviews via simple Natural Language Processing for each trail and determine a mean composite score.
) Use linear regression modeling methodologies including Statsmodels OLS to determine the relationship between a trail’s features and its’ popularity.
) Perform feature engineering and regularization via LassoCV to remove multicollinearity amongst those features and optimize the model.
) Apply that model to trails that are described as “lightly trafficked”, to find trails which would be expected to be popular based on their combination of features, but just haven’t been discovered yet.
Findings
A linear regression model was fit to the trail’s stats with the number of reviews (and hence, popularity) serving as the target variable. The model yielded a list of the most influential features on a trail on it being popular. These included there being a fee, having a high sentiment analysis score, it being rocky, and having a scramble and no shade, amongst others.
I interpret those important features like this:
A fee: If the most popular trails have a fee to use, this indicates they are likely located inside National Parks. As many National Parks are closed due to COVID, or may be very busy, it is even more important to find alternatives.
Sentiment analysis score: Since all trails have roughly the same score out of 5 stars, its hard to gather a lot of reliable information about their quality from this rating alone. By using natural language processing to analyze the written text reviews themselves, I was able to gain an actual useful metric in determining how people actually feel about the trail. The higher the score (on a scale of -1=very negative to +1=very positive), the stronger people felt positively toward the trail, which was super useful in finding hidden gems.
Rocky/scramble/no shade: What this says to me is that the very popular trails take place above tree line! It’s on those more difficult hikes with higher elevation gain that you encounter these features. And with higher elevation, you’ll likely get better views! As it turns out, people love these tougher trails.
The R² of this model was optimized to 0.19. Though this isn’t a very high score, you can see below that this is because the relationship between trail features and popularity simply isn’t linear. The residuals plot below showing the difference between the predicted popularity values and actual values demonstrates this pretty clearly (if this were linearly dependent, residuals would all fall in a fairly horizontal bar around 0!) So what’s actually determining a trail’s popularity if not it having all the right features of a popular trail?
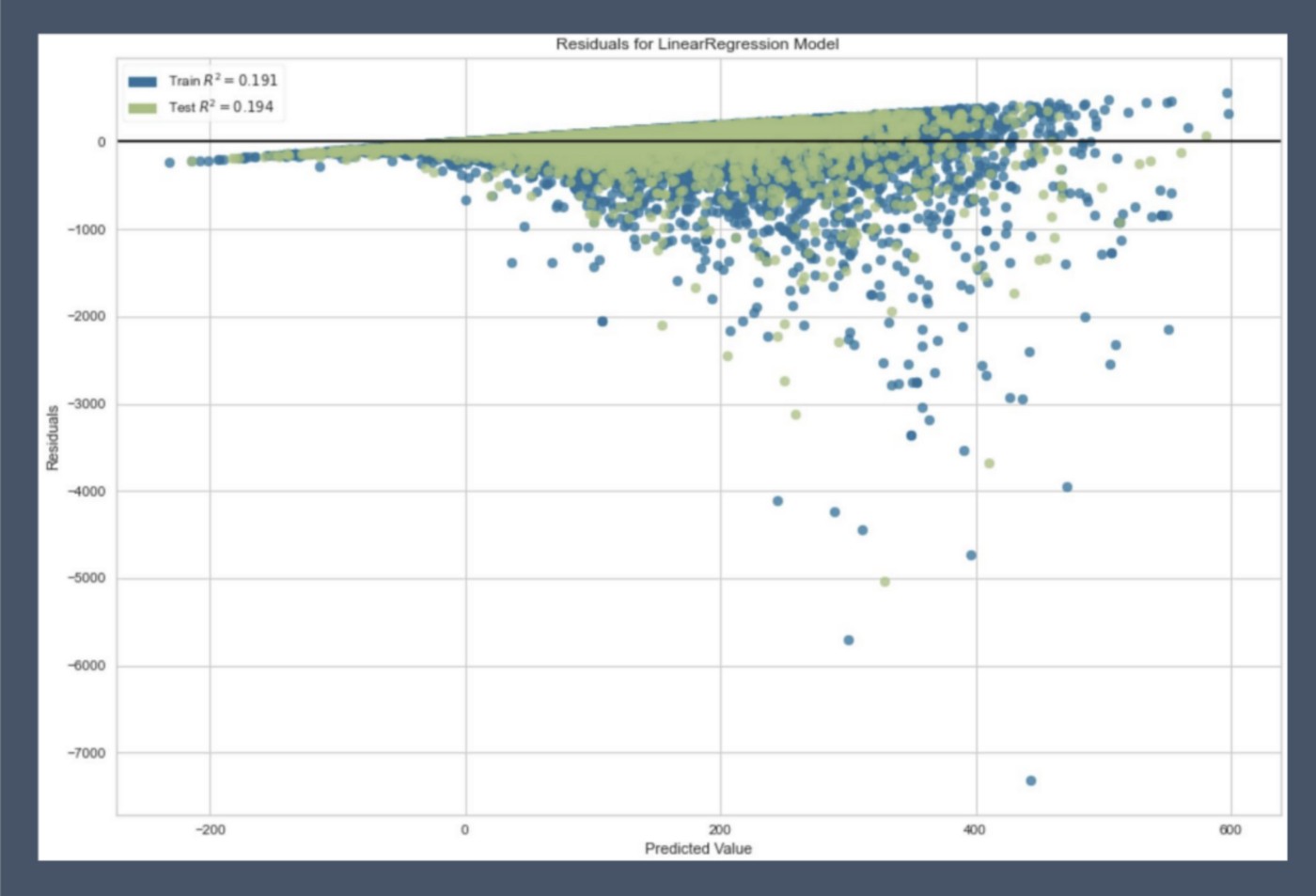 My key finding was that the search algorithm to look for trails shows the trails with the most reviews first and foremost, which leads to a form of recursive confirmation bias. If all trails have roughly the same rating, users will turn to the reviews to determine whether a trail is good, will choose to do one with a lot of reviews, hence feeding in to the loop of making the very few busiest trails even busier. Meanwhile, other similar trails may have plenty of opportunity but go neglected.
My key finding was that the search algorithm to look for trails shows the trails with the most reviews first and foremost, which leads to a form of recursive confirmation bias. If all trails have roughly the same rating, users will turn to the reviews to determine whether a trail is good, will choose to do one with a lot of reviews, hence feeding in to the loop of making the very few busiest trails even busier. Meanwhile, other similar trails may have plenty of opportunity but go neglected.
So What Makes a Trail Popular?
There are tens of thousands of hikes in the US, but the search algorithm always offers viewers the most popular hikes first. Trails with the most reviews get the most hikes, and hence even more reviews; while lesser known trails may be just a good, but are harder to find on the website, and hard to know for sure whether they’ll be a good trail if they have so few ratings.
So what makes a trail popular? Ultimately, the search algorithm does.
It’s time we break out of that feedback loop, and find some amazing alternative hikes where we can avoid the crowds. But how will you know if a trail is going to be worth your time? Well, I used Machine Learning to do that work for you.
I fit the best model on a subset of trails which were designated as being “lightly trafficked”, and the R² for these trails was 0.08. This was actually encouraging, considering that these are specifically a selection of trails which aren’t popular, but according to this, given their features, should be.
A potential area of future work for this project could be fitting a polynomial features model instead of a linear one. Early exploration into this method yielded a promising R² improvement to 0.26, but did induce some feature collinearity by duplicating features, that would need to be feature engineered out. I’m looking forward to continuing this work once I have more machine learning tools at my disposal! But I’m absolutely thrilled to present you with this list of the best lesser-known trails in America as my very first end-to-end data science project.
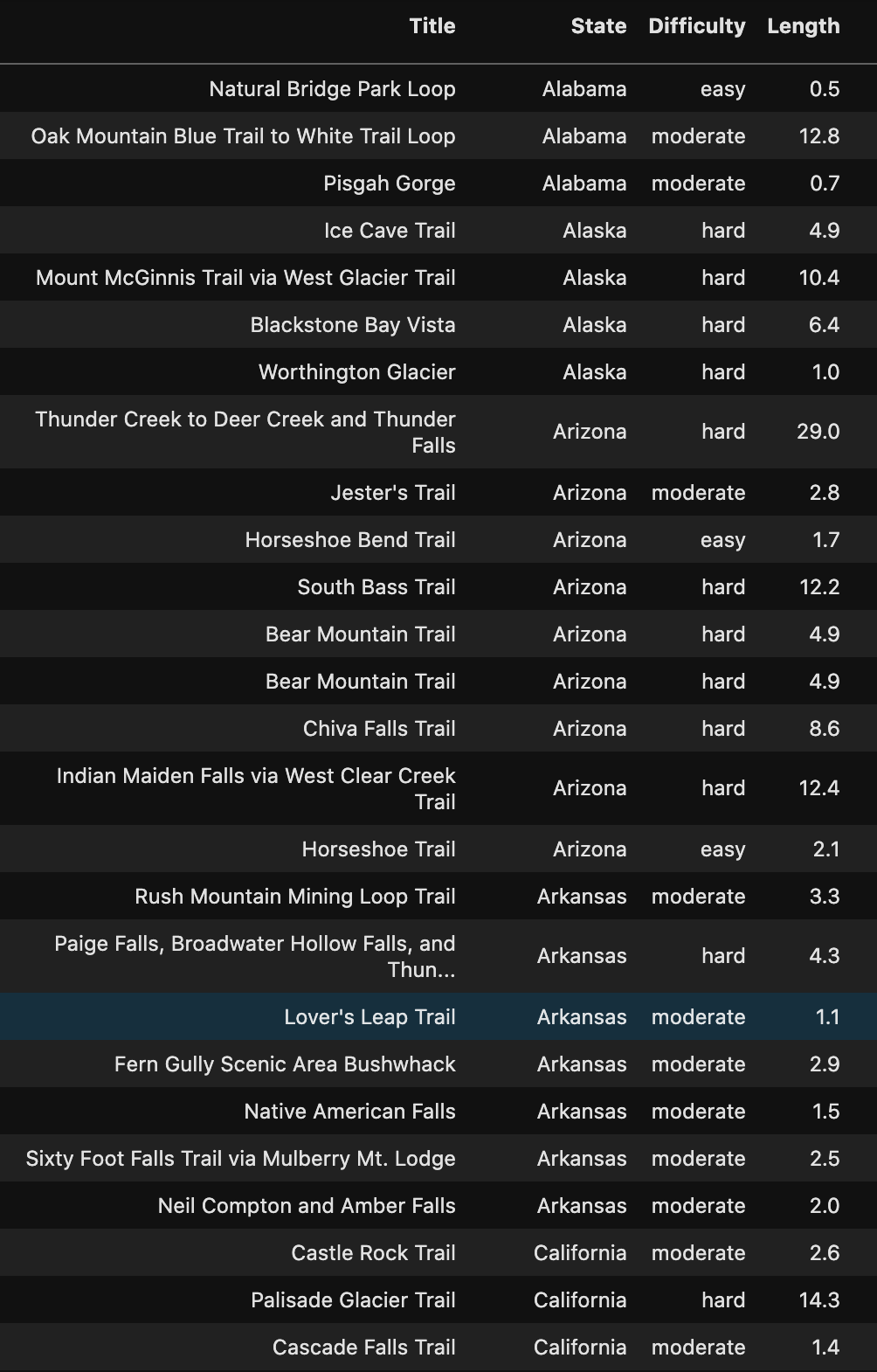
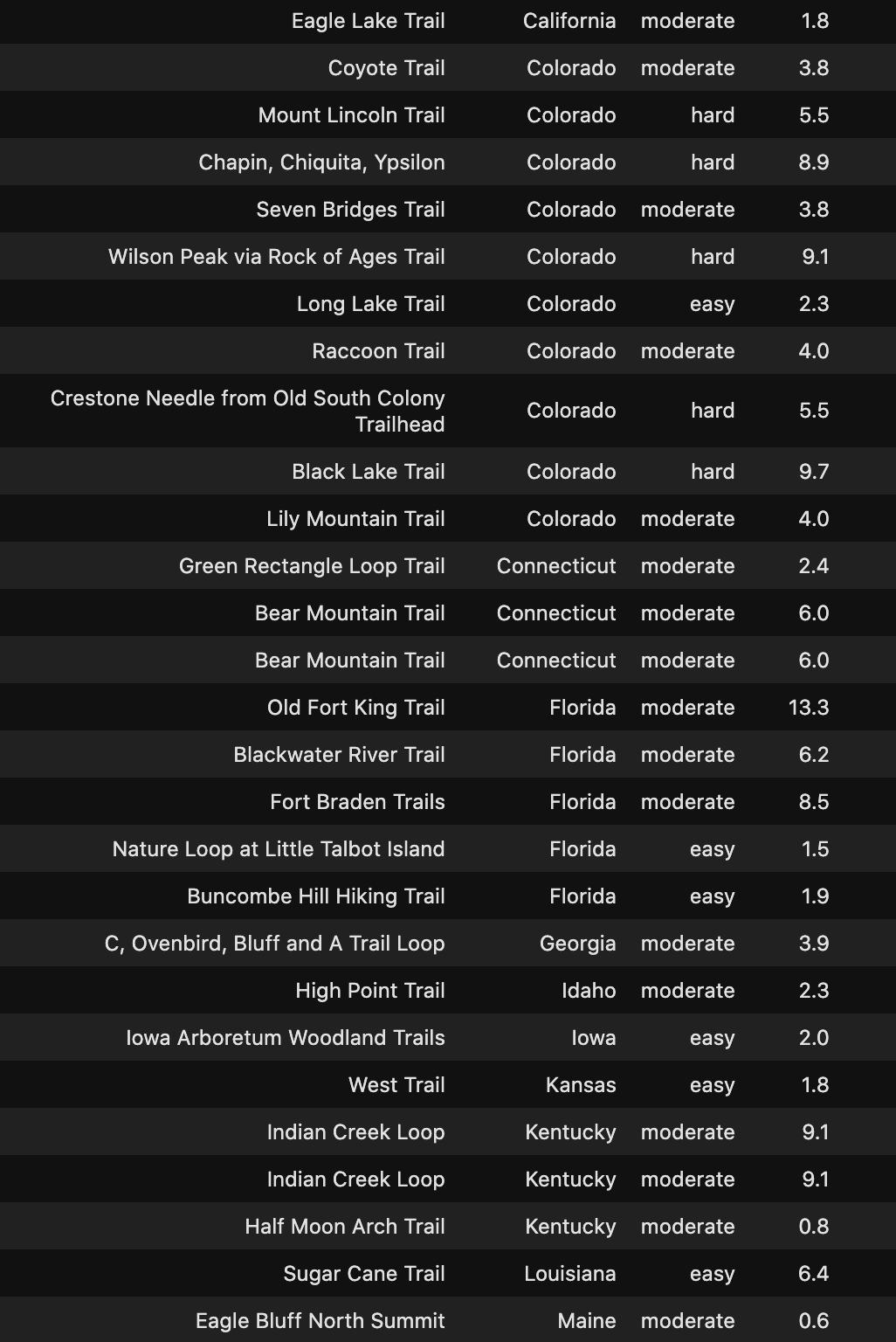
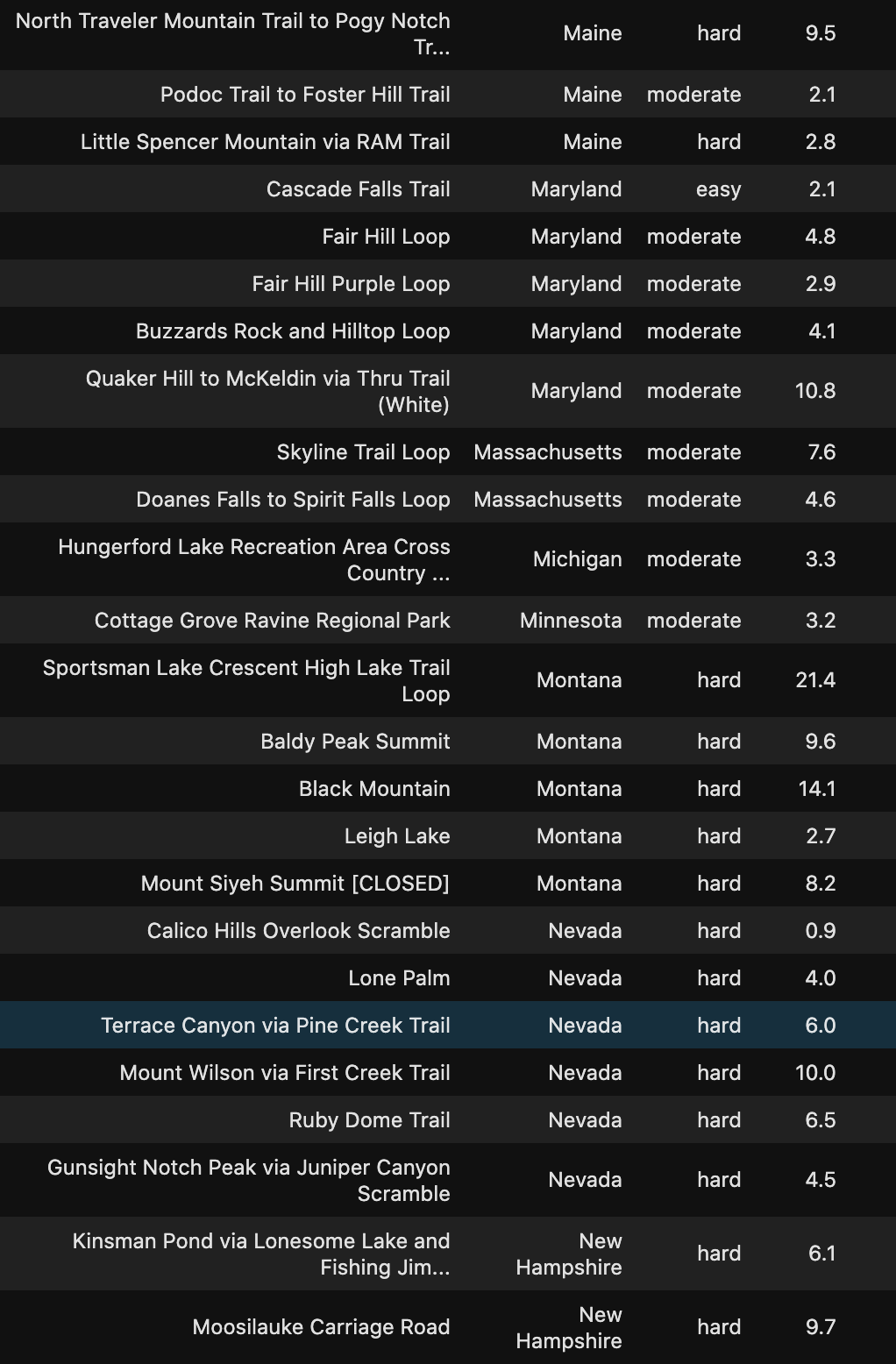
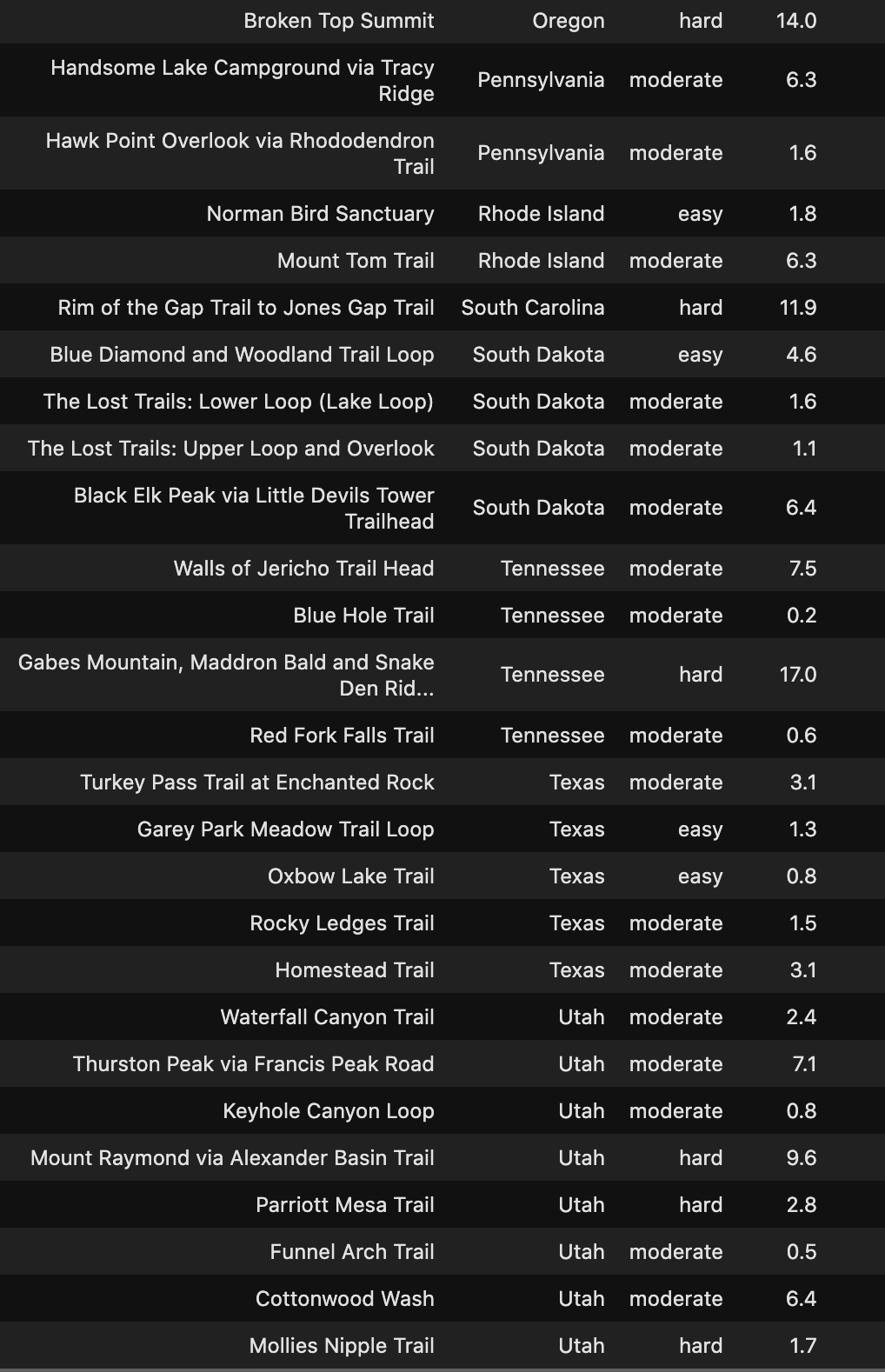
Hike The Trails
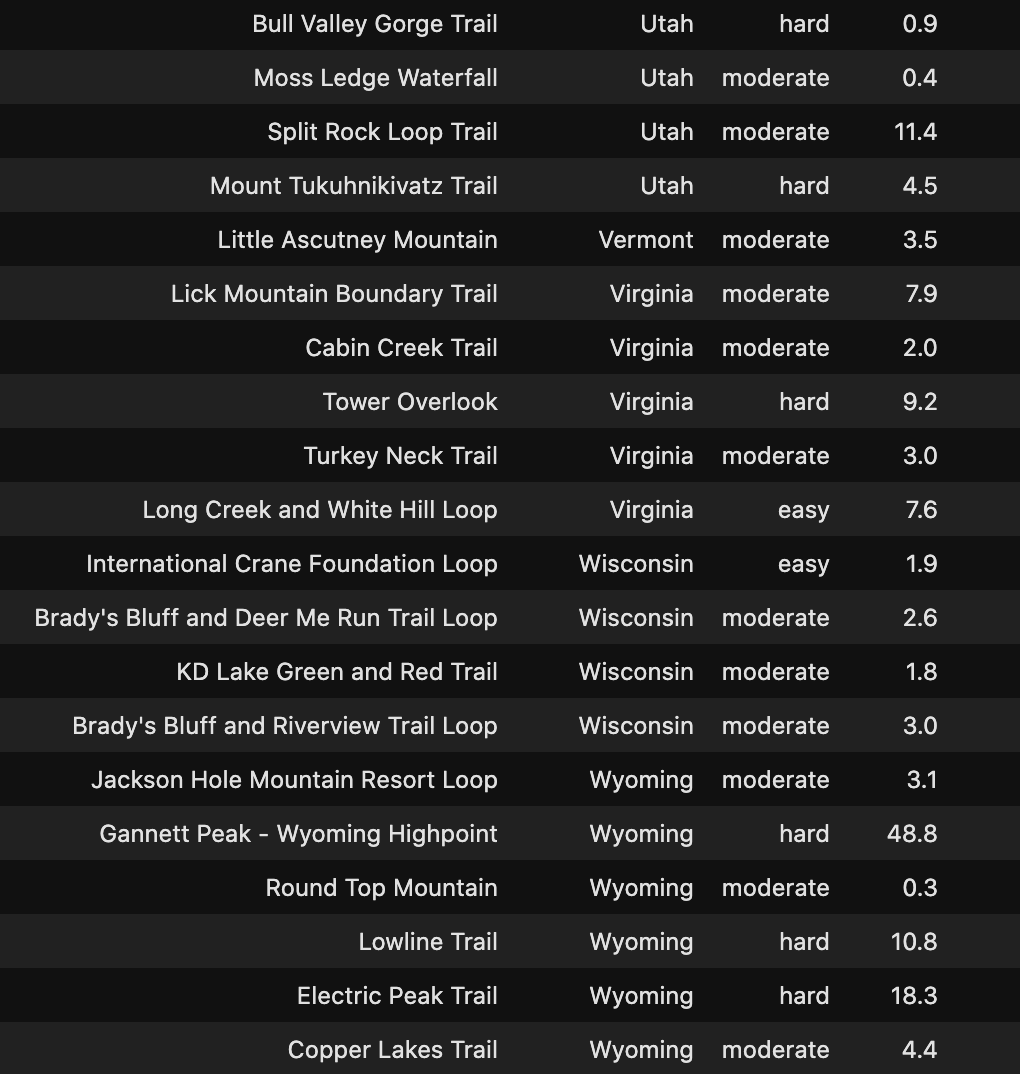
Check out the Hidden Gems in your State below!